
Parcourons ensemble les méandres de la Search Console
Si vous êtes sur cette page, vous connaissez déjà la définition du budget de crawl : il s’agit du temps que Google est prêt à consacrer à l’exploration de vos pages. Optimiser celui-ci est très précieux pour votre SEO, car il détermine le nombre de pages maximales qu’un robot d’exploration acceptera de parcourir.
Il existe de nombreux facteurs qui peuvent limiter cette exploration, plus ou moins connus. Bien entendu, l’autorité du domaine rentre dans l’équation. Plus votre site est perçu comme complet, pertinent et bien linké, plus les robots de Google seront prêts à y consacrer du temps. D’autres critères moins connus entrent en jeu. Si un Googlebot estime que votre site est trop lent, il limitera ses crawls pour ne pas créer une surcharge sur le serveur. La vitesse de vos pages a donc un impact énorme sur votre référencement.
L’objet de cet article est, en complément de notre guide complet sur la Search Console, de déterminer grâce à un outil officiel de Google quel budget crawl le moteur de recherche est prêt à consacrer à vos sites web. Découvrez avec nous cette notion essentielle du marketing digital !
Comment accéder aux informations de crawl sur la Search Console ?
Véritable couteau suisse du SEO, cette interface regorge de ressources pertinentes pour mieux comprendre comment vos pages sont explorées par un Googlebot. Vous trouverez de premiers indices intéressants dans la section “Pages”, qui vous indiqueront quelles URLs n’ont pu être indexées, ainsi que les raisons du blocage de l’indexation des pages :
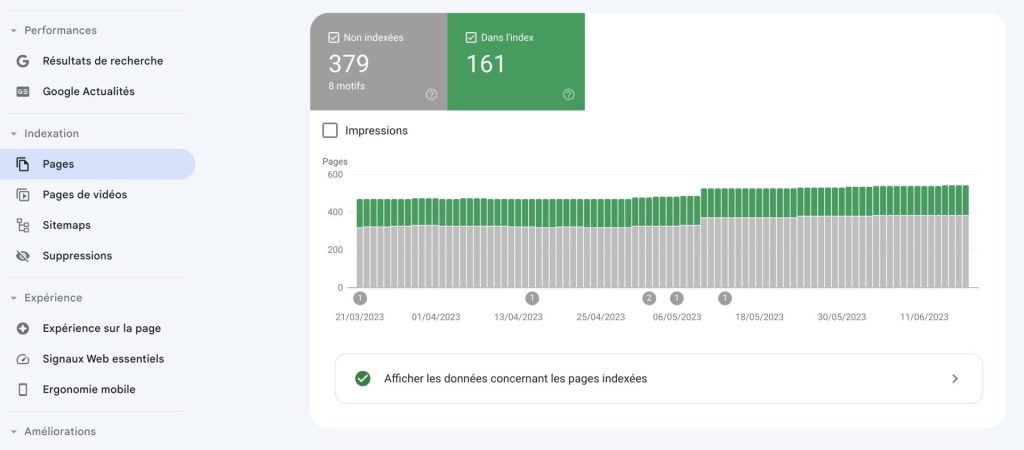
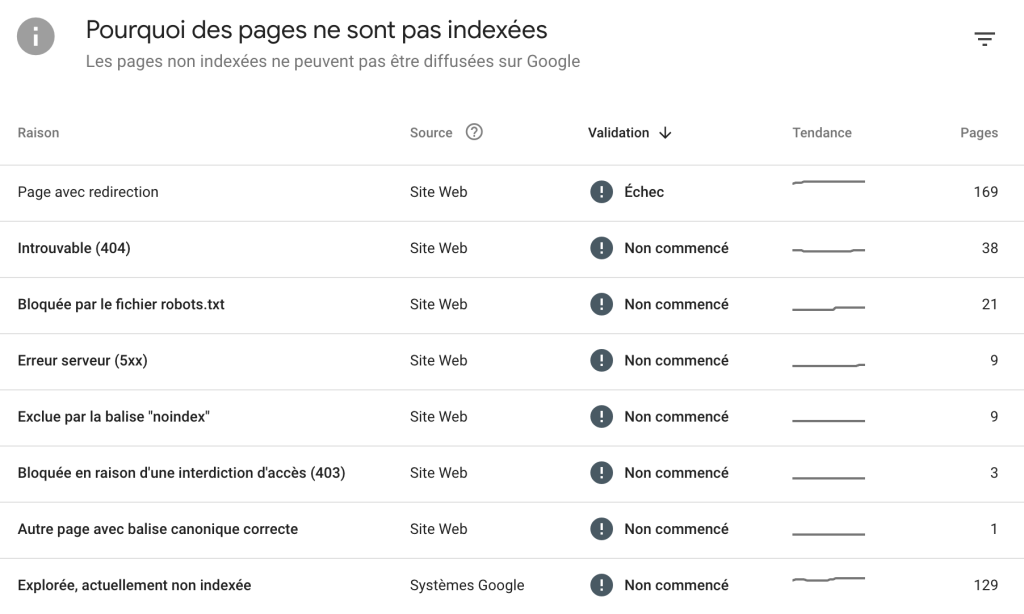
Sur les autres sections vous pouvez faire d’autres actions, comme préciser votre Sitemap… Mais ce n’est pas ici que vous trouverez les données les plus intéressantes sur votre budget de crawl.
Il existe des statistiques d’exploration, spécifiquement conçues pour donner un aperçu des différents blocages rencontrés par les robots. Cette fonctionnalité est quelque peu cachée dans l’interface. Elle ne se situe pas directement dans le menu : vous devez cliquer sur “Paramètres” puis sur “Ouvrir le rapport” dans l’encadré “Statistiques sur l’exploration”.

Comprendre les statistiques d’exploration
La première chose qui saute aux yeux quand vous arrivez sur cette section, c’est ce grand graphique qui figure en tête de la page :
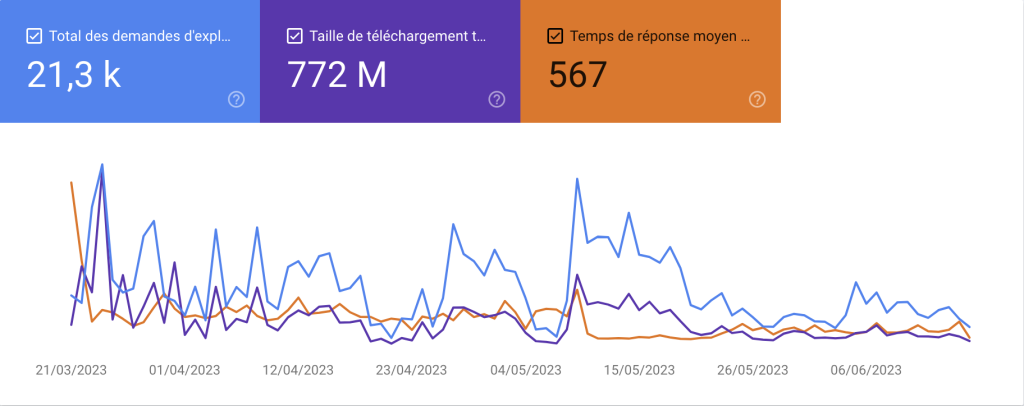
Il vous fournit trois premières informations pertinentes :
- Le total des demandes d’exploration : il s’agit de l’ensemble des requêtes d’exploration que votre site a reçu au cours des 90 derniers jours
- La taille de téléchargement totale : sur la même période de temps, on mesure la taille totale des fichiers qu’un robot a récupéré sur votre site web. Cela comprend vos fichiers HTML, mais aussi vos images, feuilles CSS et scripts JS. C’est un chiffre plus révélateur du budget crawl que les demandes d’exploration, car la vitesse de téléchargement peut différer grandement d’une page à l’autre. Cela ne comprend pas les ressources déjà en cache.
- Le temps de réponse moyen : exprimé en millisecondes, c’est le temps de chargement moyen que prend un Googlebot pour accéder à une page. Comme vous vous en doutez, plus ce chiffre est faible, mieux c’est. Ce chiffre ne tient compte ni du temps d’affichage de la page, ni de la durée nécessaire pour extraire les fichiers.
Ces chiffres sont déjà très intéressants en soi. Elles permettent de voir à la source, de manière objective, comment les robots de Google perçoivent votre site et s’il y a un blocage. Si vous voyez un temps de réponse de 2000 millisecondes ou plus, c’est qu’il y a un gros problème de chargement à corriger : votre serveur est excessivement lent dans la délivrance de ces pages
Ces statistiques sont également pertinentes à des fins de comparaison d’une période à une autre. Si vous voyez le poids des fichiers récupérés nettement augmenter ces derniers temps, c’est probablement qu’il y a une optimisation à apporter à ce niveau. Souvent ce genre de situation est provoqué par un nombre restreint d’éléments, comme par exemple un fichier JavaScript beaucoup trop lourd.
Vérifier les erreurs de crawl
Ces statistiques ne sont qu’un premier aperçu de la manière dont sont explorées vos pages. D’autres zones vous montrent, URL par URL, quels facteurs peuvent bloquer le SEO de votre site. Leurs origines sont diverses. Cela peut concerner le robots.txt, des erreurs dans les codes HTTP, ou bien encore une limite spécifique au type d’appareil utilisé… Bref, vous aurez toutes les informations possibles sur ce qui empêche les moteurs de recherche d’explorer vos URLs convenablement.
Regardons en premier lieu l’état de l’hôte :

Dans la Search Console, en cliquant sur cet encadré, vous tomberez sur une page qui vous donnera plus de détails sur d’éventuelles difficultés rencontrées par les robots lorsqu’ils tentent d’accéder à votre site web.
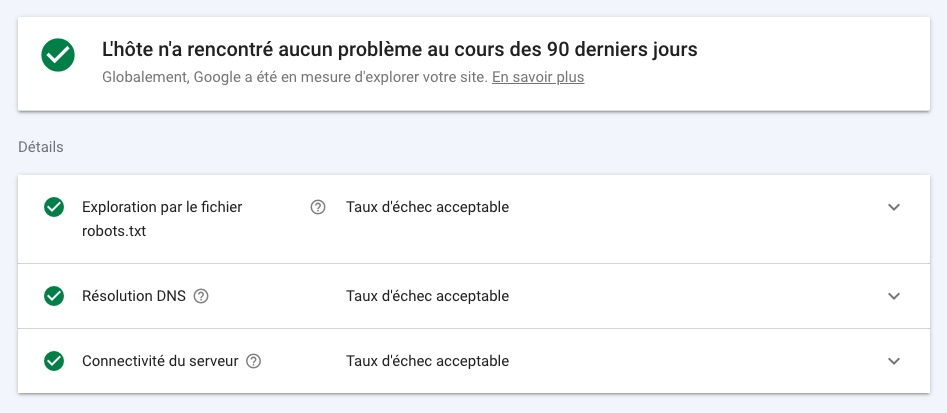
Le taux d’échec, autrement dit le pourcentage de fois où un robot de crawl n’a pas pu remplir l’une de ces trois tâches, est représenté sous la forme d’un graphique évoluant de jour en jour. Trois problèmes peuvent être remontés :
- L’exploration par le fichier robots.txt : c’est un échec quand Google demande à accéder à ce contenu et n’y parvient pas. Le robots.txt est très important car il indique au Googlebot s’il ne doit pas accéder à une URL spécifique, ou un répertoire. Si sa demande ne renvoie ni fichier valide, ni code 404, le moteur de recherche peut aller jusqu’à interrompre son exploration.
- La résolution DNS : c’est un échec quand le serveur DNS n’est pas parvenu à faire de redirections vers vos sites. Ce genre d’erreurs est dû à un problème de configuration du serveur. Cela se résout au niveau de l’hébergeur.
- La connectivité du serveur : c’est un échec quand le serveur, au-delà des redirections DNS, n’a pas répondu ou ne l’a fait que partiellement. Pour corriger ces erreurs, vous devez trouver le problème au niveau du serveur. Par exemple, si celui-ci n’est pas connecté à internet… Oui, ça arrive.
Optimiser votre budget de crawl grâce à ces infos
Si vous revenez en arrière, vous trouverez plus bas le détail des demandes d’exploration :
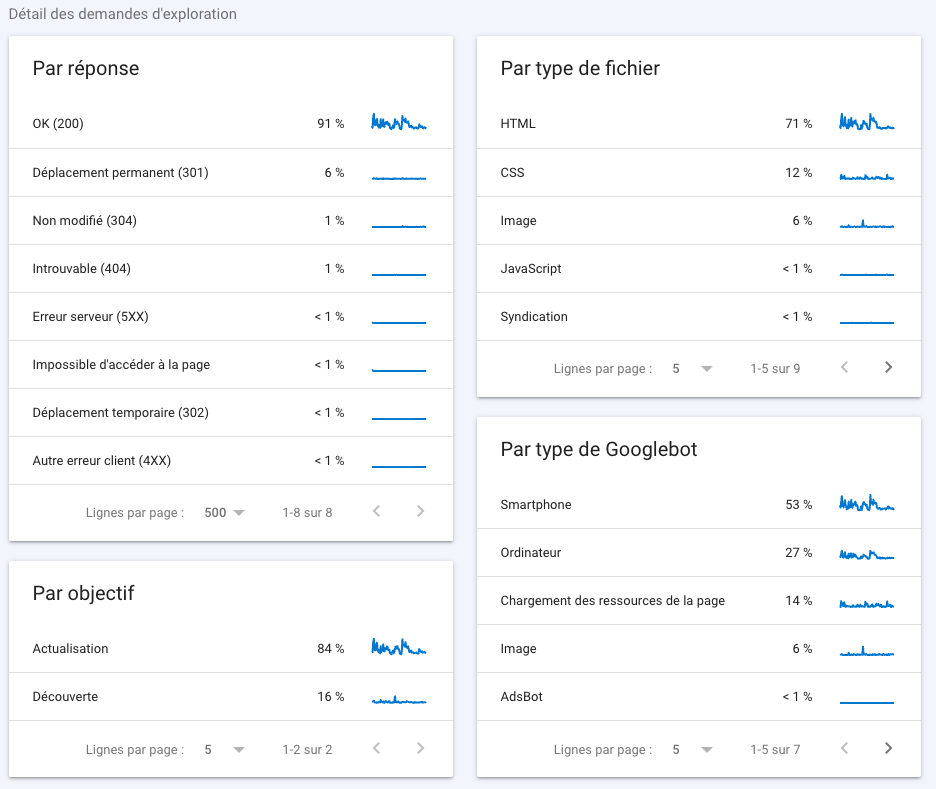
Ce sont les données les plus importantes car elles vous permettent de savoir en détail si les crawlers ont pu accéder à vos contenus. Elles permettent également de faire une analyse du budget crawl potentiellement perdu sur des pages inutiles. Revenons plus en détail sur chaque tableau et les taux qui les composent.
L’analyse “par réponse” vous donne une idée des potentielles difficultés rencontrées au cours du crawl de vos sites. Il n’existe qu’un seul et unique code HTTP permettant d’indexer une page : le code 200. Ainsi, dans l’exemple ci-dessus, 91% des pages rencontrées sont indexables. Autrement dit, 9% de votre budget crawl est perdu dans des pages non conformes. Pour optimiser cette limite imposée par Google, nous vous recommandons de retirer tous liens internes pointant vers ces mauvaises pages.
L’analyse “par type de fichier” vous donne une idée de la répartition du budget crawl sur les pages HTML et les autres contenus. Vous n’atteindrez jamais les 100% de fichiers HTML car vous avez besoin d’un design CSS et d’images pour que votre site s’affiche correctement. De même, les scripts sont parfois nécessaires pour faire tourner certains sites. Gardez toutefois en tête qu’il n’y a qu’une page HTML en mesure de se positionner sur les résultats de recherche textuels… Cette répartition est parfois très informative sur l’optimisation de votre thème WordPress.
Le rapport “par objectif” vous permet de connaître la répartition entre le contenu découvert depuis une nouvelle URL et le contenu mis à jour depuis une URL déjà connue. Notez que ces statistiques ne tiennent pas compte de la qualité des contenus, ni de la fréquence d’actualisation de votre site. Leur intérêt est relativement limité…
La répartition “par type de Googlebot” est plus intéressante. Google n’a pas qu’un seul robot de crawl. Son processus d’indexation passe par plusieurs visites sur votre site, afin de répondre à des objectifs spécifiques : vérifier la compatibilité mobile du site, la vitesse de chargement des ressources, récupérer les images… Si le temps de chargement est le pourcentage le plus élevé, cela signifie que vos performances de vitesse peuvent encore s’optimiser. Dans un monde idéal pour votre référencement, le smartphone doit représenter entre 25 et 50% de l’exploration.
Conclusion : une ressource gratuite très pertinente
Si l’étude du budget crawl ne représente qu’une partie de votre SEO, celle-ci est particulièrement importante. Comme elle détermine si Google peut facilement explorer votre site, elle a un impact fondamental sur l’ensemble de votre stratégie marketing. A quoi bon proposer un contenu de qualité pour votre référencement, si vos pages sont inaccessibles aux moteurs de recherche ?
La Search Console a ceci d’unique qu’elle est un outil officiel de Google. Vous avez donc la certitude que les informations présentées sont directement celles perçues par ses robots d’indexation. En regardant en détail chaque indication, vous pouvez optimiser vos liens internes pour permettre d’explorer plus facilement vos pages.
Toutefois, l’étude du budget crawl ne s’arrête pas là. Des solutions tierces plus complètes, comme Botify, sont utilisées par nos consultants pour booster votre SEO. Pour bénéficier d’audits de qualité qui génèrent des résultats puissants et durables, faites appel à notre agence !



 sont arrivée en France !")

