
Vision fantasmée de l’écran d’un développeur JavaScript
Pendant longtemps, cet article de blog aurait été le plus court du monde. Nous aurions simplement répondu “non” et serions passés à d’autres activités typiques des années 2000, telles que répéter des centaines de fois un mot-clé sur une page, ou écrire en blanc sur fond blanc pour avoir un texte uniquement visible par Google.
Sauf que voilà, nous vieillissons et Google aussi. Si les deux “optimisations” mentionnées ci-dessus sont obsolètes, nous ne pouvons plus être aussi catégoriques concernant le JavaScript. Aujourd’hui les référenceurs vont vous donner une réponse un peu plus longue, pour le coup aussi utilisée dans les années 2000 : “ça dépend”.
L’objet de cet article est donc de comprendre en quoi consiste le JavaScript, pourquoi les moteurs de recherche ont toujours eu du mal à comprendre cette technologie et qu’est-ce qui a changé avec le temps. C’est technique, mais nous serons pédagogues. Suivez le guide !
Quel est l’impact du JavaScript sur l’indexation d’un site ?
Pour répondre à cette question, il faut déjà bien comprendre ce qu’est le JavaScript. Il s’agit d’un langage de programmation utilisé pour le Web. Cela le distingue du HTML, qui n’est pas un programme mais un simple langage de balisage. Les robots de crawl peuvent très facilement comprendre les pages en HTML, car ce n’est que du code qui indique comment est structurée la page et son texte.
Pour le JavaScript, les choses ne sont pas aussi simples. C’est un langage principalement utilisé pour ajouter des fonctionnalités interactives aux sites web. Il permet également de communiquer avec les serveurs, afin de mettre à jour dynamiquement les informations affichées sur la page. Comprendre le JavaScript pour un robot, ce n’est donc pas juste scanner les balises qui le composent… C’est faire tourner un programme informatique et l’interpréter comme un Humain le ferait.
Google est aujourd’hui capable d’accomplir cette tâche, mais il y a certaines limites. Si celles-ci ne sont pas respectées, le SEO du site peut être gravement impacté. Pour une fois, ce n’est pas une décision arbitraire du moteur de recherche. C’est juste de la logique élémentaire : si le JavaScript ne permet pas aux robots d’accéder au moindre contenu, il n’y a aucune raison que Google ne tienne compte de cette page.

Quelles bonnes pratiques mettre en place ?
Utilisez un code JavaScript accessible
Pour cela, incluez ce code dans des fichiers externes plutôt que dans des balises <script> directement inclues dans la page HTML. Cela facilite le travail d’interprétation de Google. Pour assurer cette accessibilité, faites des liens vers vos fichiers JS directement depuis la page HTML, par l’intermédiaire de l’attribut “src” de la balise <script>.
Proposez une solution de secours pour les navigateurs qui n’ont pas le JavaScript activé
Si vous vous assurez que votre site fonctionne correctement sans JS, vous n’aurez pas de problèmes de référencement naturel. Si l’élément le plus important pour Google est lisible, à savoir le contenu textuel et ses liens hypertextes (<a href=”https://exemple.com”>), alors vous êtes tranquilles. Pour cela vous pouvez utiliser des balises <noscript>. Celles-ci sont conçues spécifiquement pour proposer un contenu alternatif en l’absence de JavaScript.
Évitez les techniques complexes de chargement asynchrone
Traditionnellement, lorsque vous ouvrez une page web, un navigateur comme Chrome télécharge l’intégralité des éléments du code source dans leur ordre d’apparition. Un chargement asynchrone permet de mettre à l’arrière-plan la récupération de certaines ressources, telles que des images ou des scripts, afin de ne pas bloquer l’affichage de la page pendant ce laps de temps. Que l’on se comprenne bien : c’est une bonne manière d’optimiser le temps de chargement. Mais utilisée à l’excès, cette technique peut rendre la page incompréhensible pour Google. Ne bloquez jamais l’affichage du texte. Par exemple, ne faites pas des injections de script à l’aide de “document.write()”.
Utilisez des URL propres et accessibles
Assurez-vous que l’ensemble des pages de votre site soit de bons vieux liens en dur. Évitez au maximum les variables, et préférez à la place quelques mots descriptifs, tels que foxglove-partner.com/titre-de-la-page. Et par pitié, ne suivez pas la mode en développant une catégorie de sites dont la simple évocation suffit à faire pâlir d’effroi tous les consultants SEO de la planète : les one-pages. Bichonnez vos référenceurs, faites plusieurs pages.
Vérifiez la compatibilité de votre site avec les outils de test de Google
C’est tout bête et ça marche très bien. Pour savoir avec certitude si vos optimisations sur le JavaScript le rendent compréhensible pour le Googlebot, passez par la Search Console. L’outil d’inspection des URL permet de vous montrer le rendu d’une page aux yeux d’un robot de d’exploration. C’est une méthode facile et fiable permettant de comprendre comment Google perçoit votre code.

Dans quel cas le JavaScript est-il adapté au SEO ?
Comment se passe un crawl de Google ? Pour une page HTML, rien de plus simple. Le Googlebot télécharge la page depuis votre serveur, pour analyser son contenu et suivre les liens internes et externes. Il récupère également le fichier CSS, afin de s’assurer que l’expérience utilisateur soit conforme à ses principes. Et puis… C’est à peu près tout. Si le code HTTP ne renvoie pas d’erreurs, n’a pas de balise Méta “noindex” et ne porte pas de canonique pointant vers une autre page, il l’indexe.
Mais alors, qu’en est-il du JavaScript ? C’est là toute la subtilité. Si le Googlebot télécharge bien le fichier JS en même temps que le CSS, ce n’est pas lui qui se charge de l’interpréter. Un second robot, appelé Google Web Rendering Service, exécute le JavaScript et l’interprète. Si vous avez quelques notions de budget crawl, vous savez déjà que cette situation n’est pas idéale. Plus Google passe du temps sur une page, moins il peut en accorder aux autres. Donc dans l’absolu, on évite le JS. Mais si on n’a pas le choix, il existe malgré tout quelques solutions…
Commençons par le scénario le plus idéal, le rendu côté serveur. De nos jours, il y a deux manières de faire tourner un code JavaScript : le SSR (Server Side Rendering) et le CSR (Client Side Rendering). Avec le SSR, c’est le serveur qui s’occupe de décoder les scripts. Cela permet d’afficher une page HTML conforme et compréhensible. Avec le CSR, c’est exactement l’inverse, puisque c’est le navigateur qui exécute le JS. Comme un robot d’exploration n’est pas un navigateur, il peut mal comprendre le code. Vous l’aurez compris, si votre JavaScript s’exécute en amont de l’affichage de la page grâce au SSR, vous êtes certains d’être bien interprétés par Google tout en économisant du budget crawl.
Toutefois, vous n’avez parfois pas le choix et devez faire du CSR. C’est particulièrement vrai pour les sites aux pages très dynamiques. Le SSR ne fonctionne qu’avec des contenus relativement statiques. Pour limiter les dégâts avec le CSR, vous pouvez faire du prerendering. Cette technique consiste à interpréter vous-même le JavaScript, pour délivrer une version statique du code à destination des robots. Cela dépend du framework, à ce titre nous vous recommandons React, Vue.js et Angular.
Quelle est la communication officielle de Google à ce sujet ?
Il existe une documentation de Google sur le JavaScript. C’est peut-être la seule source qui vaille la peine, puisqu’elle provient directement de la firme de Mountain View. Et là pour le coup on a de la chance, ils sont assez prolixes et très pédagogues. Alors que dit Google exactement sur ce problème ?
Quand on consulte ses conseils aux développeurs, on se rend compte qu’il met beaucoup en avant le dynamic rendering. Il ne doit pas être confondu avec le prerendering évoqué plus haut. Cette technique ne consiste pas à préparer à l’avance une version statique d’une page, mais au contraire à générer dynamiquement les éléments du DOM au moment de la demande de l’utilisateur. Le pré-rendu n’est pas une mauvaise chose, mais il n’est pas adapté à certaines situations. Par exemple, si une partie de la page affiche des informations sur l’utilisateur, vous devez faire du dynamic rendering pour permettre cette mise à jour en continue.
Le principe est assez simple, et peut être résumé par ce graphique proposé par Google :
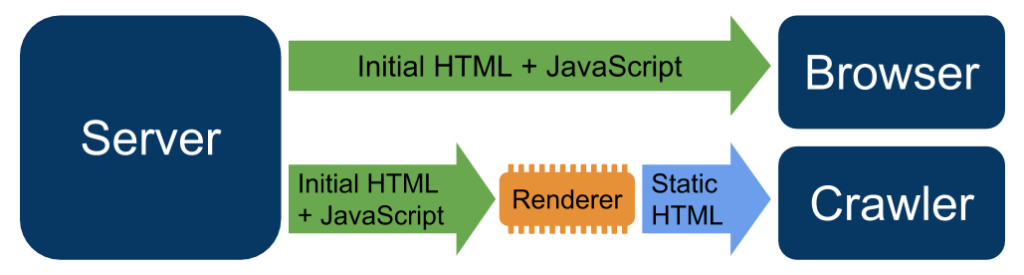
L’affichage dynamique consiste à proposer une page différente aux crawlers par rapport au navigateur. Si le User Agent d’un robot est repéré, le serveur ne propose pas directement la page HTML avec du JavaScript, mais s’occupe de “rendre” cette page, c’est-à-dire exécuter le code et proposer une version statique. Tant que ce n’est pas utilisé pour proposer aux moteurs de recherche un contenu différent de ce que voit l’internaute, c’est parfaitement autorisé par Google.
Cette solution est très avantageuse, car hormis une légère latence due à la création de cette page statique par le serveur, le budget crawl n’est pas impacté. Vous utilisez donc le plein potentiel du temps que Google est prêt à consacrer à votre site, tout en proposant un contenu dynamique aux utilisateurs.
Les recommandations des experts Foxglove
Vous vous en doutez, nos recommandations ne diffèrent pas avec ce qui vient d’être dit. Nous vous avons proposé différentes solutions, qui tiennent compte d’un contexte. En fonction de la nature de votre site et de ses fonctionnalités, différents cas de figure peuvent s’appliquer.
Ce qu’il faut retenir de tout cela, c’est que pour allier SEO et JavaScript, vous devez mettre de côté votre âme d’artiste. Vous n’avez pas besoin d’être créatifs. La seule chose que vous puissiez faire, c’est suivre scrupuleusement la recette de cuisine, en tenant compte de vos nécessités. C’est pas très sexy, mais ça permet d’indexer vos pages en toute situation ! Consultez notre checklist SEO qui vous permettra de vérifier tous les points techniques de votre site !



 sont arrivée en France !")

